SLI — Service Level Indicators
Auf dieser Seite erfahren Sie, welche Service Level Indicators (SLI) wir für Kundenprojekte einsetzen, wie wir sie messen und wo die Grenzen dieser Messungen liegen. Wir veröffentlichen diese Informationen, damit Sie als Kunde nicht nur die Zielwerte, sondern auch die Methodik, die Einschränkungen und die Interpretation der Metriken nachvollziehen können.
Diese Seite dient der Information. Die aufgeführten SLI- und SLO-Werte sind typische Richtwerte für betreute Projekte und ersetzen nicht die individuellen Vereinbarungen aus Vertrag, SOW und SLA.
So lesen Sie diese Seite
Warum SLI für Ihr Unternehmen wichtig sind
SLI, SLO, SLA — wie hängt das zusammen?
Was wir messen.
Numerische Kennzahlen, die das tatsächliche Nutzererlebnis widerspiegeln: Verfügbarkeit, Antwortzeiten, Fehlerquoten, Core Web Vitals. SLI sind Fakten, die von Monitoring-Tools erfasst werden — keine subjektiven Einschätzungen.Worauf wir hinarbeiten.
Interne Zielwerte für jeden SLI. Zum Beispiel: „API-Antwortzeit — maximal 300 ms für 95 % der Anfragen". SLO setzen die Qualitätslatte, die wir täglich überwachen und vierteljährlich überprüfen.Was wir garantieren.
Formelle Verpflichtungen, die vertraglich festgehalten werden. Wenn SLO unser interner Standard ist, dann ist das SLA ein Versprechen an den Kunden — mit Verantwortung bei Nichteinhaltung. Mehr zu unserem SLAGrundprinzip: SLI liefern die Daten für SLO, SLO bilden die Grundlage für SLA. Ohne verlässliche Indikatoren sind alle Garantien nur leere Worte. Deshalb fangen wir bei den Messungen an.
Was wir messen
Kernindikatoren
| Indikator | Was er zeigt | Wie wir messen | Richtwert (SLO) |
|---|---|---|---|
| Uptime (Verfügbarkeit) | Anteil der Zeit, in der der Service erreichbar ist und korrekt antwortet | Anteil erfolgreicher HTTP-Antworten (2xx/3xx) an der Gesamtzahl synthetischer Checks | ≥ 99,5 % (Standard), ≥ 99,8 % (Ziel) |
| Latency (Antwortzeit) | Geschwindigkeit der Serverantwort auf eine Nutzeranfrage | Perzentile P50, P95, P99 über alle Anfragen im Zeitraum | P95 < 300 ms (API), P95 < 2 s (Seite) |
| Error Rate (Fehlerquote) | Anteil der Anfragen, die mit einem Serverfehler enden | Prozentsatz der 5xx-Antworten an der Gesamtzahl der Anfragen | < 0,1 % |
| First Response Time | Wie schnell das Team auf ein eingehendes Ticket reagiert | Zeit von der Ticketerstellung bis zur ersten inhaltlichen Antwort | ≤ 20 Min. (S1, Geschäftszeiten) |
Core Web Vitals
| Metrik | Was sie misst | Schwelle „gut" | Unser Tool |
|---|---|---|---|
| LCP (Largest Contentful Paint) | Ladegeschwindigkeit des Hauptinhalts der Seite | ≤ 2,5 s | Lighthouse CI |
| INP (Interaction to Next Paint) | Reaktionsfähigkeit der Seite auf Nutzerinteraktionen | ≤ 200 ms | Lighthouse CI |
| CLS (Cumulative Layout Shift) | Visuelle Stabilität — keine „springenden" Elemente | ≤ 0,1 | Lighthouse CI |
Ergänzende Indikatoren
| Indikator | Was er zeigt | Richtwert (SLO) |
|---|---|---|
| TTMR (Time to Mitigation/Restore) | Zeit vom Beginn eines Vorfalls bis zur Wiederherstellung | ≤ 4 Std. (S1), ≤ 8 Std. (S2) |
| Deployment Success Rate | Anteil der Deployments ohne Servicebeeinträchtigung | ≥ 99 % |
| Saturation (Auslastung) | Nutzung der Serverressourcen: CPU, RAM, Festplatte | CPU idle > 10 %, RAM < 85 %, Festplatte > 10 % frei |
| SSL/Domain Expiry | Überwachung der Laufzeiten von Zertifikaten und Domains | Warnung ≥ 30 Tage vor Ablauf |
Die Werte in den obigen Tabellen dienen als Basisrichtwerte. Für ein konkretes Projekt werden sie nach dem Onboarding, der Architekturanalyse, dem Lastprofil und der Kritikalität der Geschäftsprozesse angepasst.
Wie wir messen: Tools und Methodik
UptimeRobot — externes Verfügbarkeitsmonitoring
Synthetische Checks von mehreren geografischen Standorten alle 1–5 Minuten:
- HTTP/HTTPS, Ping, Port-Checks, DNS- und SSL-Monitoring
- Sofortige Benachrichtigungen bei Ausfall via E-Mail, Slack, Telegram
- Historische Uptime-Daten für die Berichterstattung
- Öffentliche Statusseiten für Transparenz gegenüber Nutzern
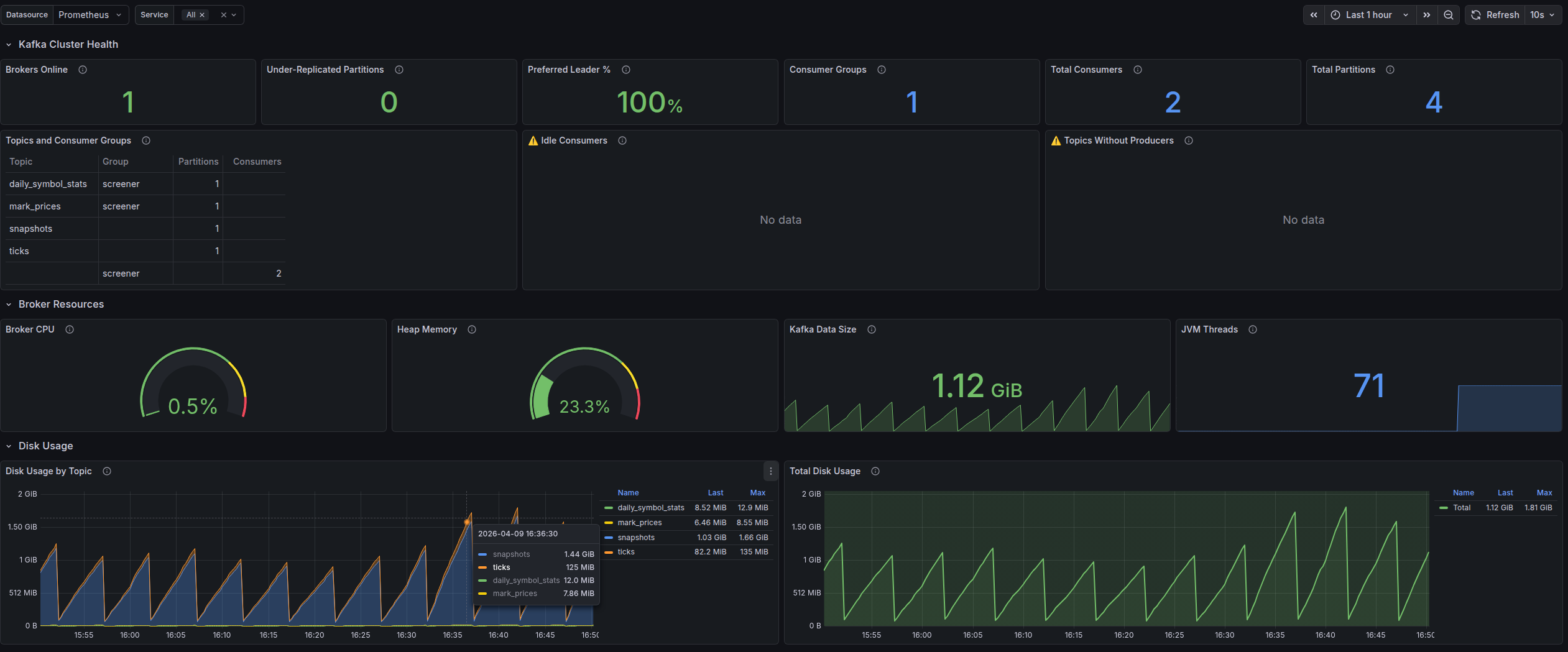
Grafana + Prometheus — Visualisierung und Analyse
Prometheus sammelt Metriken von Servern und Anwendungen, Grafana visualisiert sie auf konfigurierbaren Dashboards:
- Latency (P50, P95, P99), Error Rate, Throughput — in Echtzeit
- Monitoring der Serverressourcen: CPU, RAM, Festplatte, Netzwerk
- Konfigurierbare Alarme bei Überschreitung von Schwellenwerten
- Historische Trends zur Erkennung von Verschlechterungen, bevor sie zum Vorfall werden
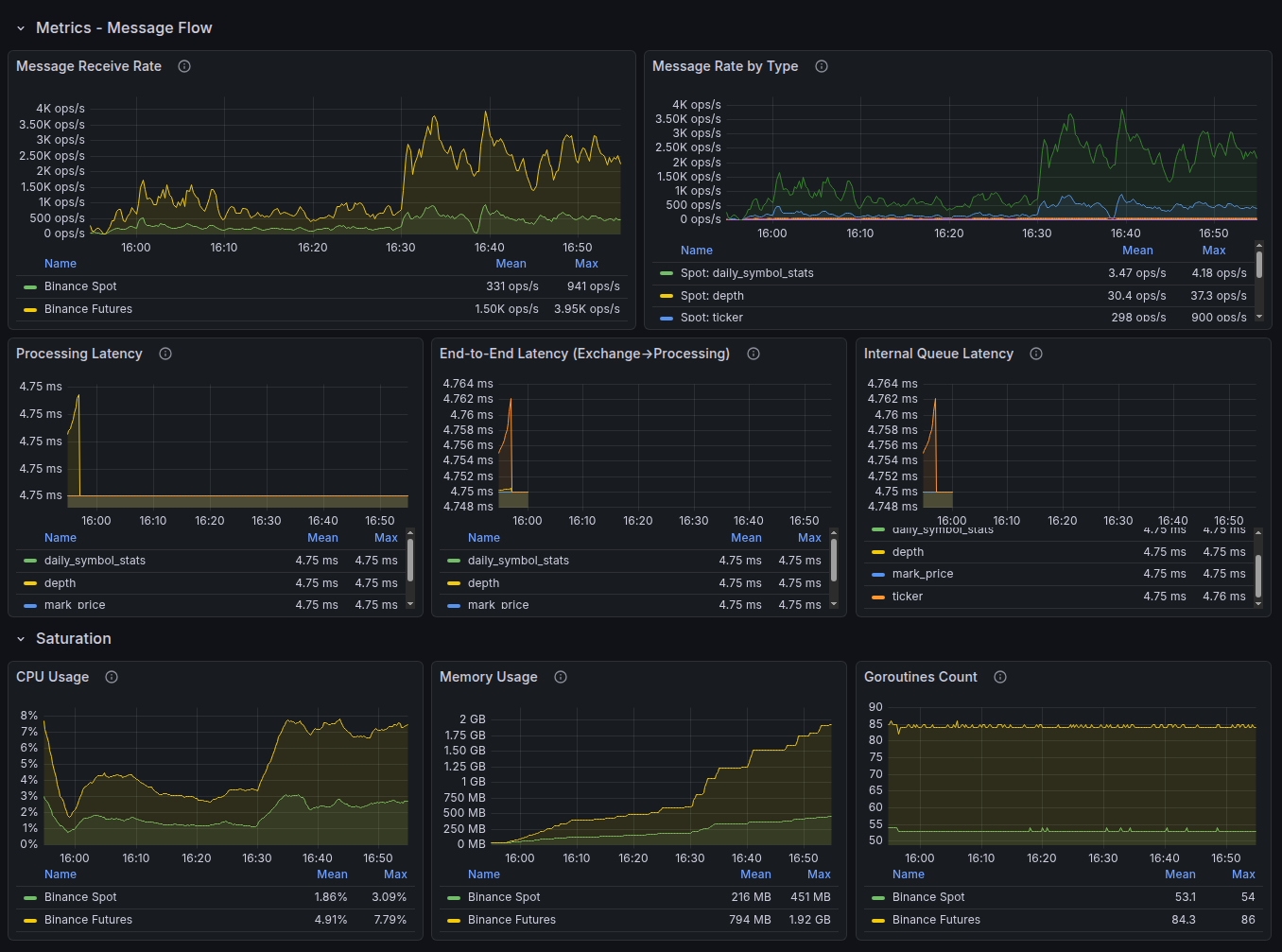
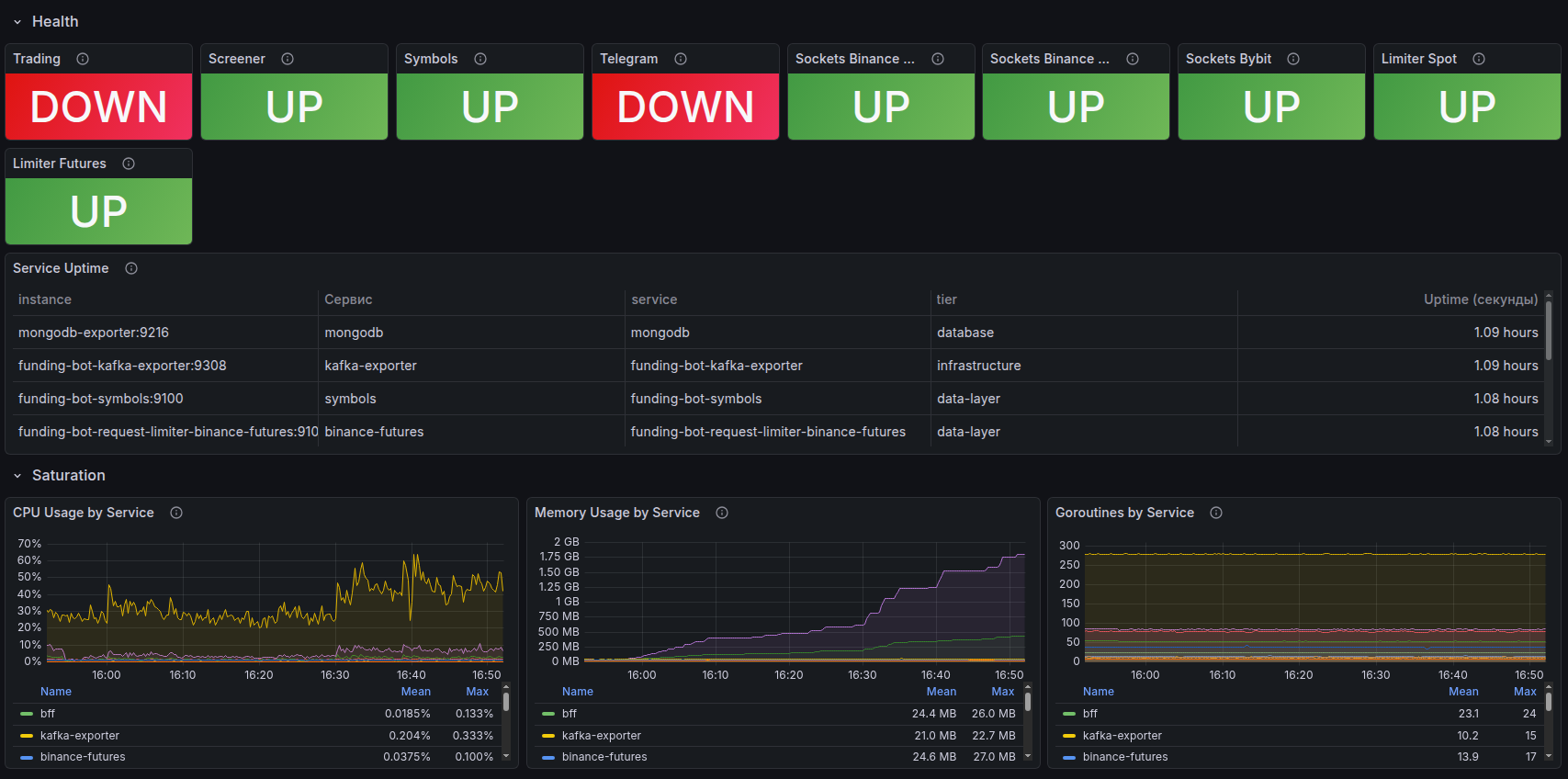
Laravel Nightwatch — Monitoring auf Anwendungsebene
Tiefgreifende Instrumentierung von Laravel-Anwendungen — direkt von den Framework-Entwicklern:
- Tracing jeder Anfrage vom Eingang bis zur Antwort
- Erkennung langsamer SQL-Abfragen und Engpässe in Warteschlangen
- Echtzeit-Monitoring von Exceptions und Fehlern
- Überwachung von Hintergrundaufgaben und Cron-Zeitplänen
Hinweis: Bei einzelnen Projekten wird als Alternative zu Nightwatch New Relic APM eingesetzt — eine umfassende Plattform für Performance-Monitoring. Die Toolwahl richtet sich nach der Projektarchitektur und den Kundenanforderungen.
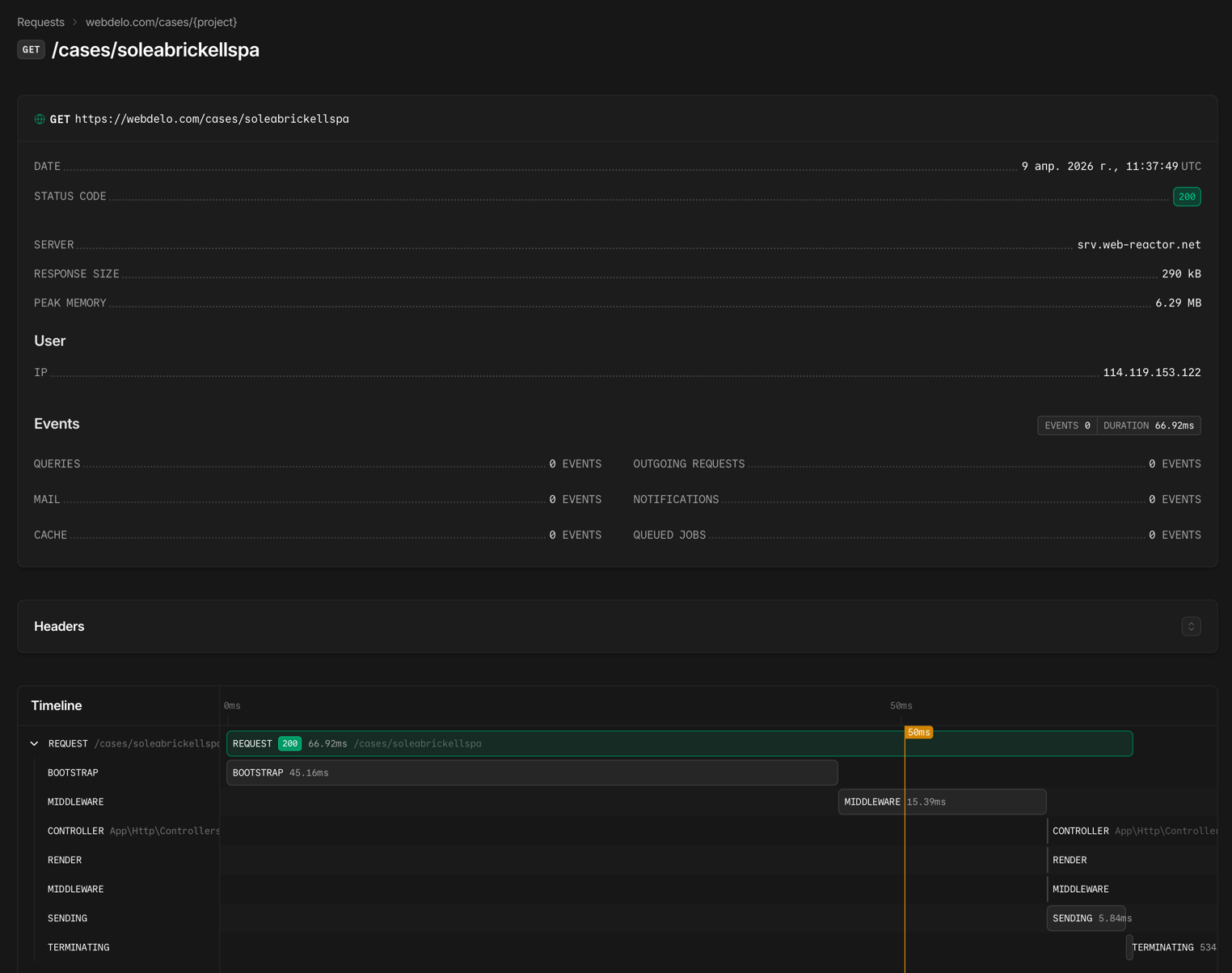
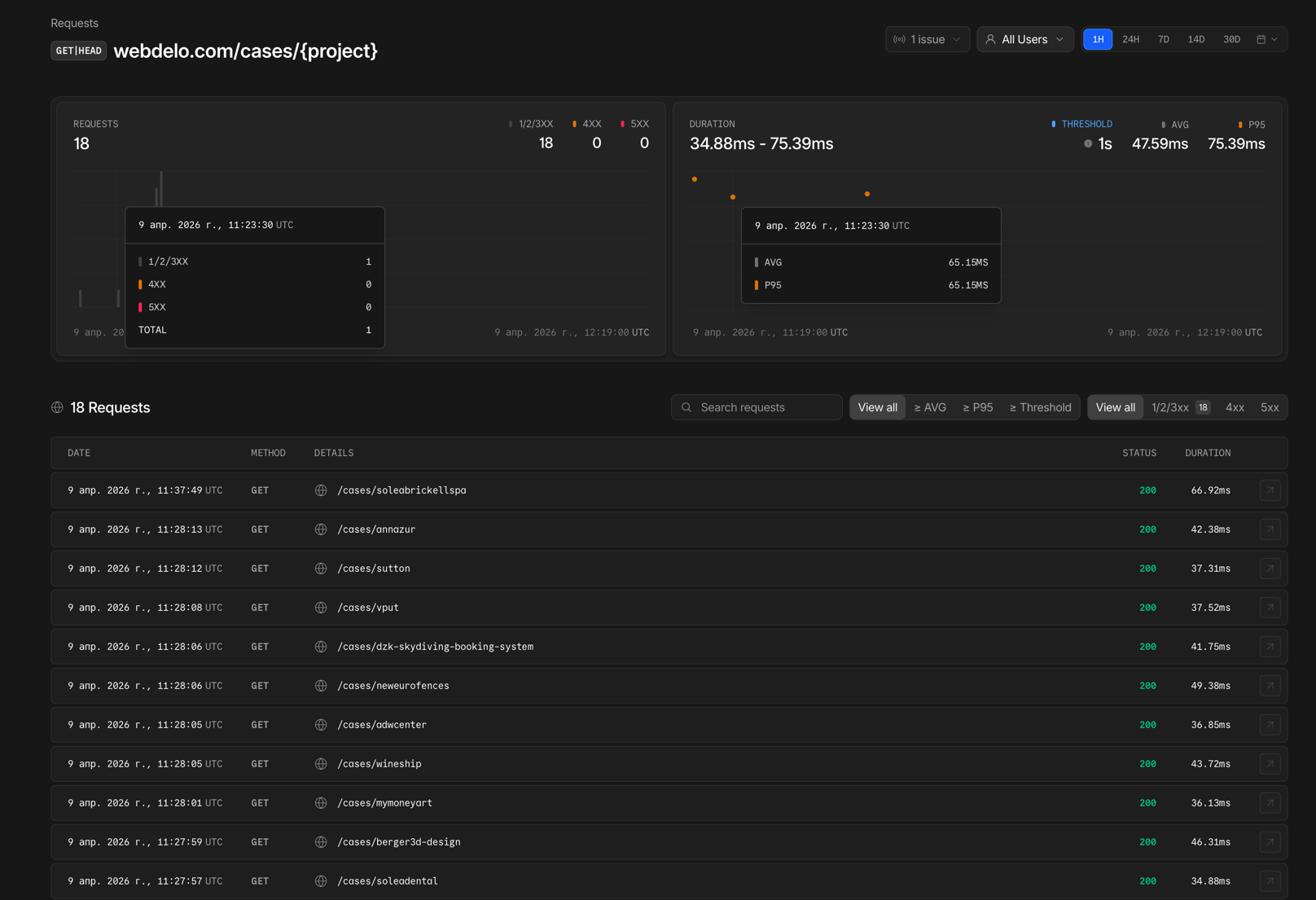
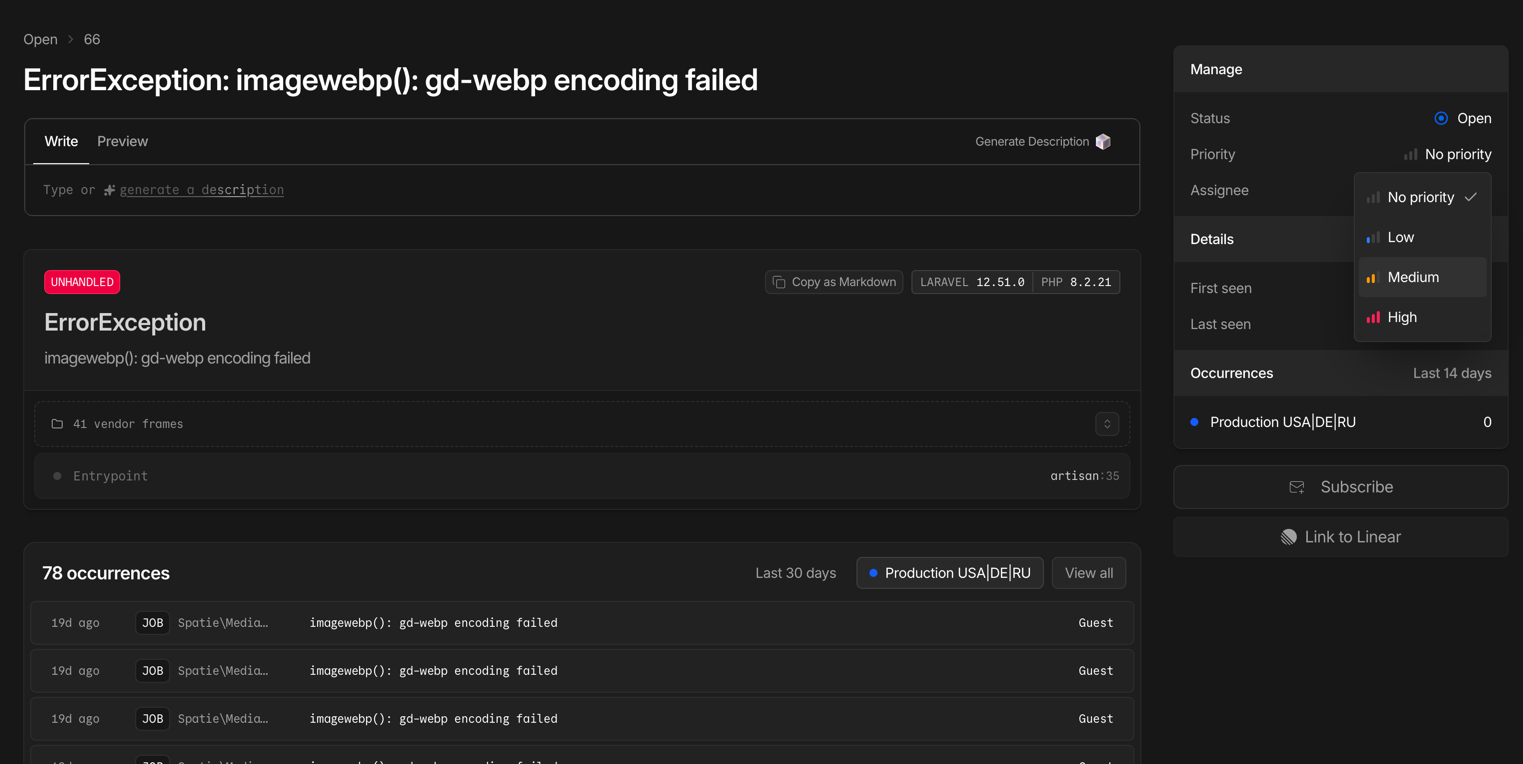
Lighthouse CI — Kontrolle der Core Web Vitals
Automatisches Performance-Audit bei jedem Deployment:
- Ausführung in der CI/CD-Pipeline von Bitbucket Pipelines
- Vergleich der Metriken mit dem vorherigen Release — Regressionen fallen sofort auf
- LCP, INP, CLS sowie Accessibility- und SEO-Audit
- Blockierung des Deployments bei kritischer Verschlechterung der Werte
Methodik
Error Budget — das Budget für zulässige Fehler
| Ziel-Uptime | Zulässige Ausfallzeit pro Monat | Zulässige Ausfallzeit pro Jahr |
|---|---|---|
| 99,5 % | ~3 Std. 39 Min. | ~43 Std. 48 Min. |
| 99,8 % | ~1 Std. 27 Min. | ~17 Std. 31 Min. |
| 99,9 % | ~43 Min. | ~8 Std. 46 Min. |
| 99,95 % | ~22 Min. | ~4 Std. 23 Min. |
Warum das für Sie wichtig ist: Das Error Budget hilft uns, Entscheidungen nicht aus dem Bauch heraus zu treffen („lieber nichts anfassen"), sondern auf Basis von Daten. Das bedeutet: Ihr Projekt entwickelt sich so schnell wie möglich — bei dem von Ihnen gewünschten Zuverlässigkeitsniveau.
Monitoring-Umfang nach Support-Plan
| Leistung | Basic | Extended | Enterprise |
|---|---|---|---|
| Synthetische Verfügbarkeitschecks (Uptime) | ✓ | ✓ | ✓ |
| Überwachung von SSL-Zertifikaten und Domains | ✓ | ✓ | ✓ |
| Benachrichtigungen bei Ausfall | ✓ | ✓ | ✓ |
| Lighthouse CI (Core Web Vitals) | ✓ | ✓ | ✓ |
| Latency-Monitoring (P50, P95, P99) | — | ✓ | ✓ |
| Error-Rate-Monitoring | — | ✓ | ✓ |
| Ressourcen-Monitoring (CPU, RAM, Festplatte) | — | Teilweise | ✓ |
| APM auf Anwendungsebene (Nightwatch / New Relic) | — | Teilweise | ✓ |
| Individuelle Grafana-Dashboards | — | — | ✓ |
| Proaktive Benachrichtigungen bei Verschlechterungen | — | ✓ | ✓ |
| Error-Budget-Tracking | — | — | ✓ |
| SLI-Berichterstattung | Auf Anfrage | Monatlich | Wöchentlich + QBR |
| Ziel-Uptime (SLO) | 99,5 % | 99,5–99,8 % | bis 99,9 %* |
Modell zur Einstufung von Vorfällen
| Stufe | Beschreibung | Erste Reaktion (SLO) | Wiederherstellung (SLO) |
|---|---|---|---|
| S1 — Kritisch | Vollständiger oder teilweiser Ausfall, ein zentraler Geschäftsprozess ist blockiert, Sicherheitsvorfall | ≤ 20 Min. (Geschäftszeiten) | ≤ 4 Stunden |
| S2 — Hohe Auswirkung | Erhebliche Beeinträchtigung mit Workarounds, Einfluss auf SEO oder Conversion | ≤ 1 Stunde | ≤ 8 Stunden |
| S3 — Mittlere Auswirkung | Defekte mit begrenztem geschäftlichem Einfluss | ≤ 4 Stunden | Im laufenden Sprint |
| S4 — Geringe Auswirkung | Kosmetische Probleme, UX-Verbesserungen | ≤ 1 Werktag | Nach Priorität im Backlog |
Transparenz und Berichterstattung
Was ein SLI-Bericht enthält
| Abschnitt | Inhalt |
|---|---|
| Uptime im Zeitraum | Tatsächlicher Verfügbarkeitsprozentsatz im Vergleich zum Ziel-SLO |
| Latency-Trends | Entwicklung der Antwortzeiten (P50, P95) mit Hervorhebung von Anomalien |
| Error Rate | Fehlerquote mit Aufschlüsselung nach Typ und Quelle |
| Core Web Vitals | Entwicklung von LCP, INP, CLS und Auswirkungen auf SEO-Rankings |
| Vorfälle im Zeitraum | Anzahl, Schweregrad, Reaktionszeit und Wiederherstellungsdauer |
| Error Budget | Wie viel Budget verbraucht wurde und wie viel noch übrig ist |
| Empfehlungen | Konkrete Maßnahmen zur Verbesserung der Kennzahlen |
Berichtsfrequenz
| Plan | SLI-Bericht | Format |
|---|---|---|
| Basic | Auf Anfrage | Zusammenfassung im Ticketsystem |
| Extended | Monatlich | PDF + Kommentare |
| Enterprise | Wöchentlich + vierteljährlicher QBR | Dashboard + PDF + Call |
Unser Ansatz für Zuverlässigkeit
Verantwortungsbereiche und Ausnahmen
Unser Verantwortungsbereich
Verantwortungsbereich des Kunden
Was SLI in der Regel nicht abdecken
Die konkreten Verantwortungsbereiche und Ausnahmen werden im Vertrag festgelegt und können je nach Projektarchitektur und gewähltem Support-Plan variieren.
